|
▒▒Š®SEO╝╝ąg(sh©┤)Ę■äš(w©┤)ųąą─Į±╠ņų„ę¬╩ŪĖ·┤¾╝ęĘųŽĒę╗Ž┬╦č╦„ę²ŪµĄ─╣żū„Ą┌ę╗éĆ(g©©)Łh(hu©ón)╣Ø(ji©”)Ą─ų¬ūR(sh©¬)Ż║╗ź┬ō(li©ón)ŠW(w©Żng)ų«┼└ŽxĪŻ
╬ęéāŽ╚üĒ┐┤ę╗Ž┬╦³Ą─Č©┴xŻ║ŠW(w©Żng)Įj(lu©░)┼└ŽxŻ©ėų▒╗ĘQ×ķŠW(w©Żng)Ēōų®ųļŻ¼ŠW(w©Żng)Įj(lu©░)ÖC(j©®)Ų„╚╦Ż¼į┌FOAF╔ńģ^(q©▒)ųąķgŻ¼Ė³Įø(j©®ng)│ŻĄ─ĘQ×ķŠW(w©Żng)ĒōūĘųš▀Ż®Ż¼╩Ūę╗ĘN░┤ššę╗Č©Ą─ęÄ(gu©®)ätŻ¼ūįäė(d©░ng)Ąžūź╚Ī╚fŠSŠW(w©Żng)ą┼ŽóĄ─│╠ą“╗“š▀─_▒ŠĪŻ┴Ē═Ōę╗ą®▓╗│Ż╩╣ė├Ą─├¹ūų▀Ćėą╬øŽüĪóūįäė(d©░ng)╦„ę²Īó─ŻöM│╠ą“╗“š▀╚õŽxĪŻ
Å─ęį╔ŽĄ─Č©┴xüĒ┐┤Ż¼░┘Č╚ų®ųļŻ¼╣╚ĖĶÖC(j©®)Ų„╚╦Č╝ī┘ė┌┼└ŽxĄ─ę╗ĘNŻ¼Č°┼└Žxų„ę¬╩Ū░┤ššę╗Č©Ą─ęÄ(gu©®)ätŻ¼ūįäė(d©░ng)ūź╚Īą┼ŽóĄ──_▒Š╗“š▀│╠ą“Ż¼▀@éĆ(g©©)▓╗ļy└ĒĮŌŻ¼ėąĮø(j©®ng)“×(y©żn)Ą─│╠ą“åTČ╝─▄ē“¬Ü(d©▓)┴óĄ─ŠÄīæ│÷üĒę╗╠ū▒╚▌^═Ļš¹Ą─ų®ųļ│╠ą“Ż¼ė├üĒ╩š╝»ŠW(w©Żng)Įj(lu©░)ą┼ŽóŻ¼│õīŹ(sh©¬)ūį╝║Ą─ŠW(w©Żng)šŠĪŻŲõīŹ(sh©¬)║▄ČÓĄ─ą┼Žó▓╔╝»▄ø╝■ę▓╩Ū▓╔ė├┴╦▀@ĘN╝╝ąg(sh©┤)ĪŻ
─Ū├┤╬ęéā?c©©)┌üĒ┐┤ę╗Ž┬ų®ųļĄĮĄū▀M(j©¼n)ąąĄ─╩▓├┤╣żū„Ż║) 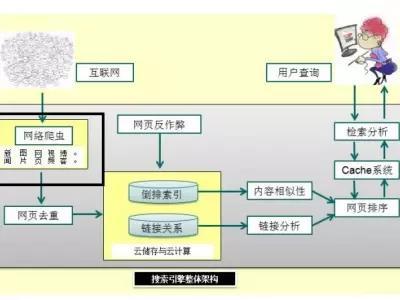
├┐ę╗ĘNŅÉą═Ą─┘Yį┤Ż¼Č╝ėąŽÓæ¬(y©®ng)Ą─ų®ųļ┼└ŽxüĒ╦č╝»Ż¼«ö(d©Īng)╚╗ĮŌ╬÷Ą─ĘĮ╩Įę▓Ė„▓╗ŽÓ═¼ĪŻ╬ęéāĮø(j©®ng)│Ż─▄ē“į┌ŠW(w©Żng)šŠĄ─╚šųŠųą┐┤ĄĮ░┘Č╚Ą─spider║═image-spiderŻ¼▓╗═¼Ą─┼└Žx└¹ė├Ųõūį╔ĒĄ─ęÄ(gu©®)ätüĒī”(du©¼)ŲõĒō├µ▀M(j©¼n)ąąĮŌ╬÷ĪŻ╝┤╩╣╩Ū▀@śėŻ¼ ╬ęéāę▓─▄ē“┐┤ĄĮ┼└Žxį┌┼└╚źĒō├µĄ─Ģr(sh©¬)║“▀Ć╩Ūėąę╗Č©Ą─ęÄ(gu©®)┬╔ąįĄ─Ż¼▀@ĘNęÄ(gu©®)┬╔ąįät╩ŪüĒūįė┌╦č╦„ę²Ūµą¦┬╩ūŅ┤¾╗»Ą─╚Ī╔ßĪŻ
īÆČ╚ā×(y©Łu)Ž╚▒ķÜvįŁätŻ║▀@éĆ(g©©)įŁät╩ŪÅ─ŠW(w©Żng)šŠūį╔Ēū÷ŲĄ─Ż¼Ė∙ō■(j©┤)ŠW(w©Żng)šŠĄ─īė╝ē(j©¬)üĒūź╚ĪĪŻę“?y©żn)ķ╬ęéāį(c©©)┌ū÷ŠW(w©Żng)šŠĄ─Ģr(sh©¬)║“Č╝ėąę╗éĆ(g©©)ā×(y©Łu)Ž╚Ą─┐╝æ]Ż¼▒╚╚ń╬ęĄ┌ę╗éĆ(g©©)Žļūī╦č╦„ę²Ūµ┐┤ĄĮĄ─Š═╩Ū╩ūĒōŻ¼Ųõ┤╬Ą─Ė„éĆ(g©©)─┐õøĒō├µŻ¼į┘Ųõ┤╬Š═╩Ūā╚(n©©i)╚▌Ēō├µŻ¼ų®ųļę▓╩Ū└¹ė├▀@ę╗³c(di©Żn)üĒūź╚ĪĪŻ
ĘŪ═Ļ╚½pagerank┼┼ą“Ż║▀@éĆ(g©©)įŁätŠ═╩Ū└¹ė├╣╚ĖĶĄ─prųĄüĒėŗ(j©¼)╦ŃĄ─ĪŻę“?y©żn)ķ├┐ę╗éĆ(g©©)ŠW(w©Żng)Ēōį┌╣╚ĖĶųąČ╝Ģ■(hu©¼)ėąę╗éĆ(g©©)įu(p©¬ng)ĘųŻ¼Ė∙Į^▀@ą®įu(p©¬ng)ĘųĖ▀Ą═üĒūź╚ĪĪŻ╚ń╣¹═Ļ╚½ėŗ(j©¼)╦ŃŠ═▒╚▌^║─┘M(f©©i)ėŗ(j©¼)╦Ń┘Yį┤Ż¼╦∙ęį╦³Š═▓╔ė├Ė▀prųĄĄ─ŠW(w©Żng)Ēōé„▀f│÷üĒĄ─µ£Įė┐ŽČ©Č╝╩Ū┐╔┐┐Ą─ĪŻ
OPICŻ©online page importance computationį┌ŠĆĒō├µųžę¬ąįėŗ(j©¼)╦ŃŻ®Ż║▀@ę╗éĆ(g©©)įŁätĖ·prųĄėŗ(j©¼)╦ŃŽÓ▓Ņ¤oÄūŻ¼į┌▓╔╝»Ą─ŠW(w©Żng)ĒōųąüĒėŗ(j©¼)╦Ń├┐ę╗éĆ(g©©)ŠW(w©Żng)ĒōĄ─ųžę¬ąįŻ¼╚╗║¾į┌▀M(j©¼n)ąąā×(y©Łu)Ž╚ūź╚ĪĪŻ
┤¾šŠā×(y©Łu)Ž╚▓▀┬įŻ║▀@éĆ(g©©)╬Ńė╣ų├ę╔┴╦ĪŻę“?y©żn)ķ┤¾æ?zh©żn)▒╚▌^Ę¹║Žą┼┘ćĄ─įŁätĪŻ
ŲõīŹ(sh©¬)╬ęéā┐╔ęį┐┤ĄĮŻ¼▀@ĘNįŁätŲõīŹ(sh©¬)╩Ūī”(du©¼)ūź╚ĪĄ─ėąŽ▐ąį║═ŠW(w©Żng)ĒōĄ─¤oŽ▐ąįĄ─ę╗éĆ(g©©)š█ųąŻ¼╝┤į┌ėąŽ▐Ą─Ģr(sh©¬)ķgā╚(n©©i)ūź╚ĪŠW(w©Żng)Įj(lu©░)ųąĖ³×ķųžę¬Ą─Ēō├µ║═┘Yį┤ĪŻ«ö(d©Īng)╚╗╬ęéāę▓ąĶę¬╚ź┴╦ĮŌŠW(w©Żng)Įj(lu©░)┼└Žx╣żū„Ą─įŁ└ĒŻ¼▀@śėĄ─įÆĖ³ėą└¹ė┌╬ęéā?n©©i)źū?span style="font-size:18px;">SEOā×(y©Łu)╗»ĪŻ
|
╦č╦„ę²Ūµ┼└Žx蹊┐┼c┼└╚źįŁät
░l(f©Ī)▓╝Ģr(sh©¬)ķgŻ║2017.01.12 ×gė[:
┤╬
0
┘Øę╗éĆ(g©©)
ŅA(y©┤)╝sSEOŅÖå¢Ę■äš(w©┤)šł(q©½ng)┬ō(li©ón)ŽĄŻ║185-1018-8870Ż©╩ųÖC(j©®)╬óą┼═¼▓ĮŻ® ŅI(l©½ng)╚Ī├Ō┘M(f©©i)VIPā╚(n©©i)▓┐šn│╠
╬─š┬üĒį┤Ż║▒▒Š®SEO╝╝ąg(sh©┤)Ę■äš(w©┤)ųąą─
╬─š┬ś╦(bi©Īo)Ņ}Ż║╦č╦„ę²Ūµ┼└Žx蹊┐┼c┼└╚źįŁät
▒Š╬─ĄžųĘŻ║http://www.szbingri.com/SEOjishu/SEOjichu/444.html
░µÖÓ(qu©ón)╦∙ėą © ▒▒Š®SEO╝╝ąg(sh©┤)Ę■äš(w©┤)ųąą─Ż©╬óą┼/QQŻ║zhizheseo/2052048546Ż®Ż¼ÜgėŁĘųŽĒ▒Š╬─Ż¼▐D(zhu©Żn)▌dšł(q©½ng)▒Ż┴¶│÷╠ÄŻĪ æ(zh©żn)┼Óė¢(x©┤n)")